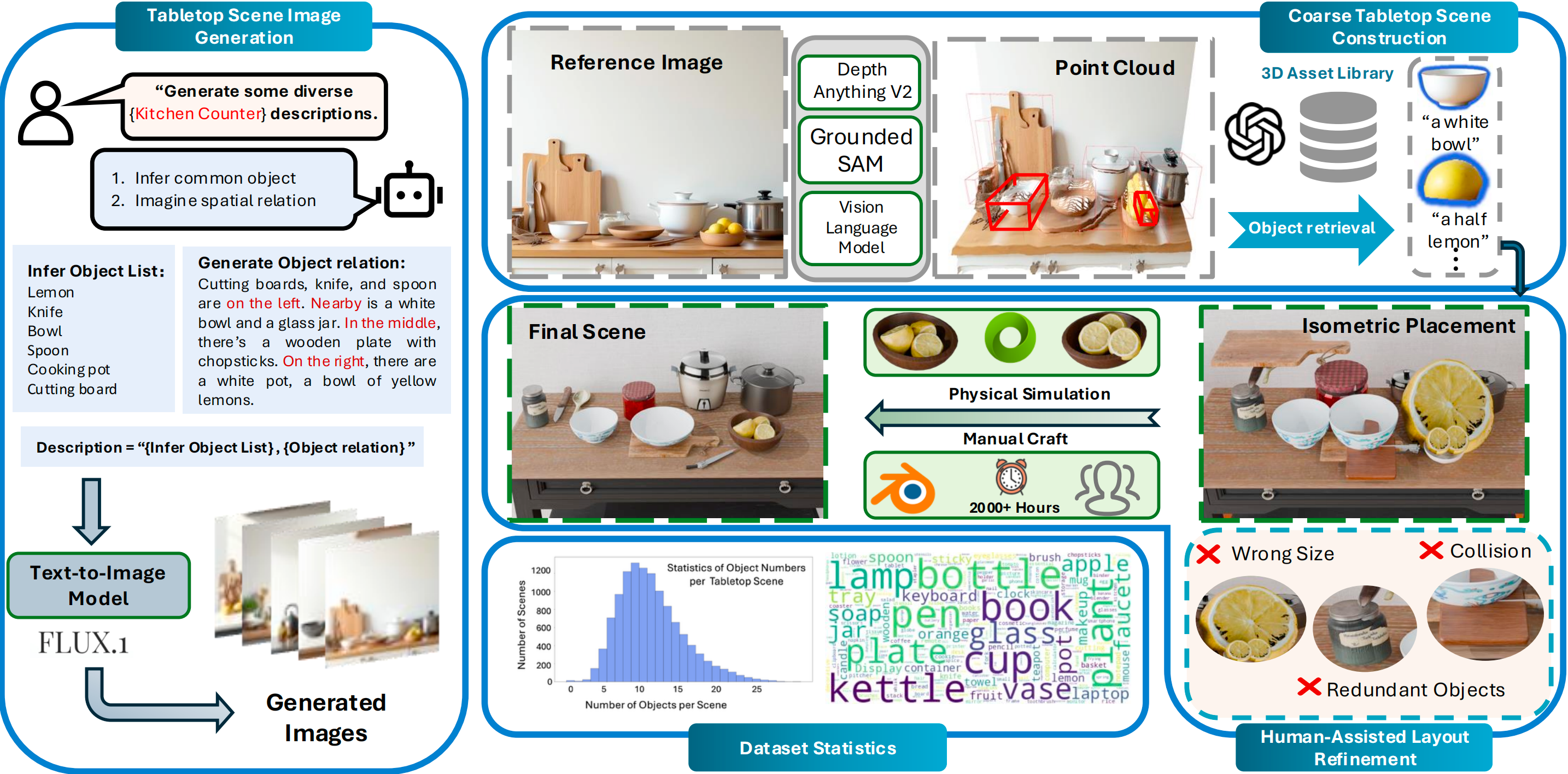
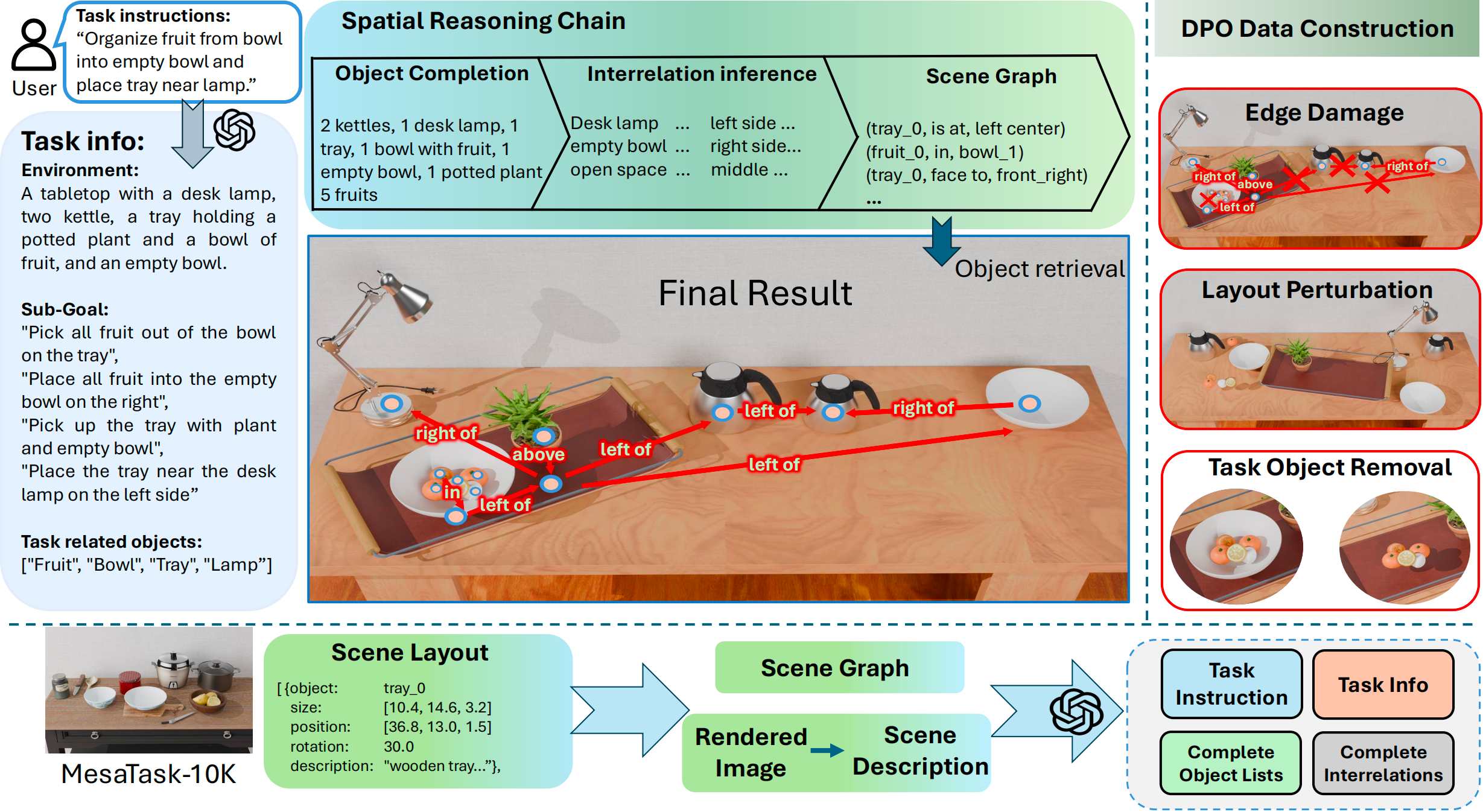
MesaTask
Towards Task-Driven Tabletop Scene Generation
via 3D Spatial Reasoning
* equal contribution, ‡ project lead, ✉️ corresponding author